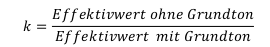
Den Effektivwert mit und ohne Grundton Effektivwert gesamt einer harmonischen Schwingung berechnet man, indem man die auf den Grundton bezogenen Amplituden der Obertöne quadriert, addiert und aus dem Resultat die Wurzel zieht:
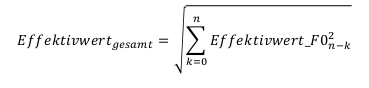
Einleitung: Die Manipulation von digitalisierten Signalen, wie wir sie z.B. in Reaktor antreffen (Mixing, Filterung, Effekte, etc.), kann man allgemein darstellen als die Funktion sog. Diskreter Systeme, die eine Eingangsfolge von Abtastwerten x(k) in eine Ausgangsfolge y(k) überführen:
Das heißt, D[x(k)] = y(k). Diskrete Systeme können sowohl hardwaremäßig als auch softwaremäßig realisiert werden. Wir wollen uns im Rahmen der Übung mit relativ einfachen diskreten Systemen beschäftigen. Dabei beschränken wir uns auf Systeme, die die Elemente Addierer, Multiplizierer und Verzögerung enthalten. Diese bezeichnet man auch als lineare zeitinvariante Systeme, da die resultierenden Folgen stets lineare Kombinationen von Eingangsfolgen sind und sich das Verhalten der Systeme in Abhängigkeit von der Zeit nicht ändert.
1. Addierer: Es gilt: y(k) = x1(k) + x2(k). Zwei Abtastwertefolgen x1(k) und x2(k) werden addiert und ergeben eine Ausgangsfolge y(k). Einem Mixing liegt immer eine Addition zugrunde.
2. Multiplizierer: Es gilt: y(k) = a * x(k). Eine Abtastwertfolge wird mit einem konstanten reellen Faktor a multipliziert.
3. Verzögerung: Es gilt: y(k) = x(k-1). Ein Abtastwert wird für eine Abtastperiode zwischen- gespeichert und dann ausgegeben. Nutze für die Aufgaben die euch schon bekannte wave_io. Für die Übung benötigt ihr außerdem eure Musik- und Sprachaufnahme, sowie eine 1kHz Sinusfunktion und Weißes Rauschen (moodle).
Ein Maß für die Verzerrung ist der sogenannte Klirrfaktor k, der für eine periodische Schwingung folgendermaßen definiert ist:
Den Effektivwert mit und ohne Grundton Effektivwert gesamt einer harmonischen Schwingung berechnet man, indem man die auf den Grundton bezogenen Amplituden
der Obertöne quadriert, addiert und aus dem Resultat die Wurzel zieht:
a. Zunächst sollt ihr eure Musikdatei um 3, 6 und 9 dB verstärken. Dies realisiert ihr durch Multiplikation der Abtastwerte mit dem entsprechenden konstanten Verstärkungsfaktor, den ihr aus der dB-Angabe berechnen müsst. Dabei wird es bei hoher
Verstärkung zwangsläufig zu einem sogenannten Clipping kommen, d.h. das Produkt aus der Originalamplitude und dem Verstärkungsfaktor ist betragsmäßig größer als der maximal darstellbare Amplitudenwert (bei 16 bit
< -32768 bzw.> 32767). In diesem Fall muss dafür gesorgt werden, dass der resultierende Wert auf genau -32768, bzw. 32767 gesetzt wird. Clipping ist akustisch als immer stärker werdende nichtlineare Verzerrung wahrnehmbar.
b. Bei welcher Verstärkung wird eine Verzerrung wahrnehmbar? Falls +9 dB nicht reichen, in 3 dB-Schritten die Verstärkung erhöhen!
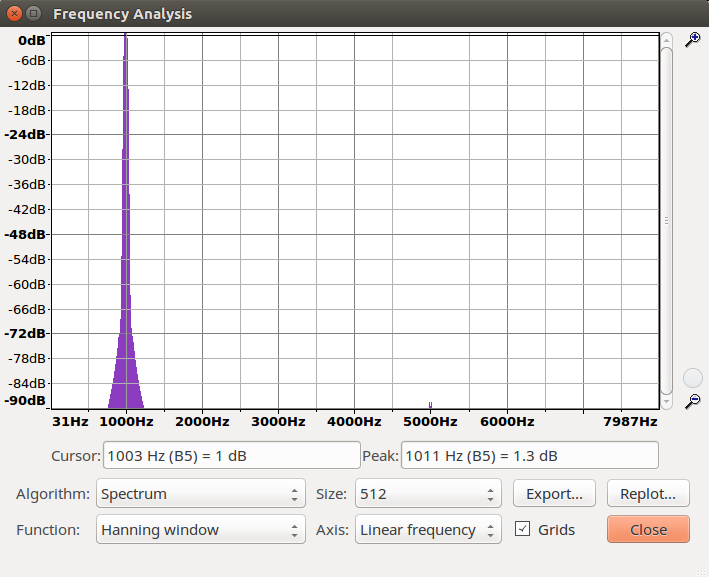
c. Ihr sollt nun die 1kHz-Sinusschwingung um 6, 9 und 12 dB verstärken und den resultierenden Klirrfaktor k berechnen. Der Klirrfaktor lässt sich aus dem Frequenzspektrum berechnen (GRAM: FFT 512, alle sichtbaren Obertöne für die Berechnung
berücksichtigen!). Beachte: Die dB-Angaben müssen aus GRAM in lineare Angaben zurückgerechnet werden.
Ins Übungsprotokoll: Sourcecode, wavs Musik und Sinus, Ausschnitte vom Clipping
(Samplitude), Frequenzspektrum der verstärkten Sinussignale (GRAM), Berechnungen
Klirrfaktor k.
private static void reinforceWAVFile(String input, String output, int decibel) throws IOException, WavFileException {
WavFile wavFile = WavFile.read_wav(input);
int validBits=wavFile.getValidBits();
long sampleRate=wavFile.getSampleRate();
long numFrames=wavFile.getNumFrames();
int numChannels=wavFile.getNumChannels();
int samples=(int)numFrames*numChannels;
short short_max = 32767;
short short_min = -32768;
for (int i=0; i < samples;i++) {
short sample = wavFile.sound[i];
short reinforcedSample = 0;
double linearfactor = linearfactorFromDecibel(decibel);
double reinforcement = sample * linearfactor;
if (reinforcement > short_max) reinforcedSample = short_max;
else if (reinforcement < short_min) reinforcedSample = short_min;
else reinforcedSample = (short)reinforcement;
wavFile.sound[i] = reinforcedSample;
}
WavFile.write_wav(output, numChannels, numFrames, validBits, sampleRate, wavFile.sound);
}
private static double linearfactorFromDecibel(int decibel) {
return Math.pow(10, ((double)decibel/20));
}
Eine Verzerrung wird bereits bei einer Verstärkung um 6 dB wahrnehmbar und bei 9 db deutlich hörbar.
3 dB |
6 dB |
9 dB |
|---|---|---|
Berechnungen Klirrfaktor k:
| Frequenz | Startpoint | 6 dB | 9 dB | 12 dB |
|---|---|---|---|---|
| 1000 | 0 | 0 | 0 | 0 |
| 3000 | n/a | -92 | -16 | -11 |
| 5000 | n/a | -89 | -33 | -26 |
| 7000 | n/a | -112 | -39 | -26 |
| Klirrfaktor | 1.408 | 0.025 | 0.079 |
Sinus Wavs:
6 dB |
9 dB |
12 dB |
|---|---|---|
Frequenzspektrum der verstärkten Sinussignale:
| 6 dB | 9 dB | 12 dB |
|---|---|---|
 |
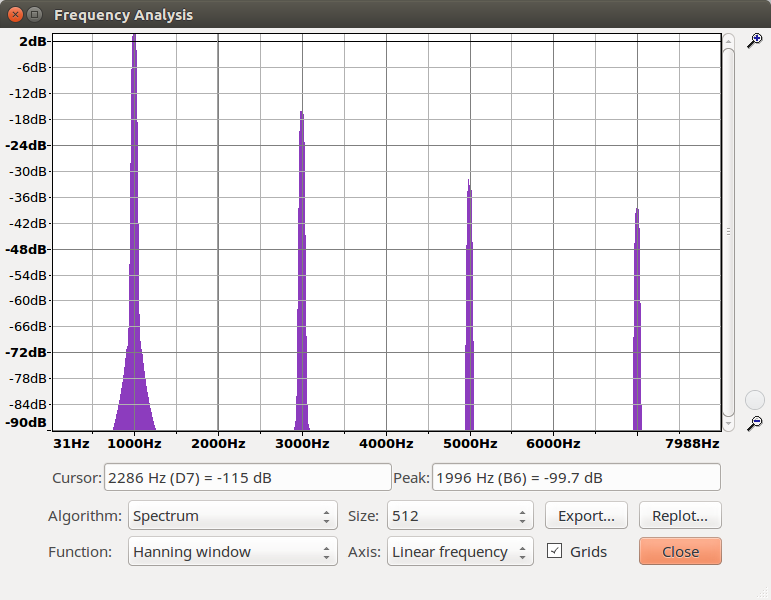 |
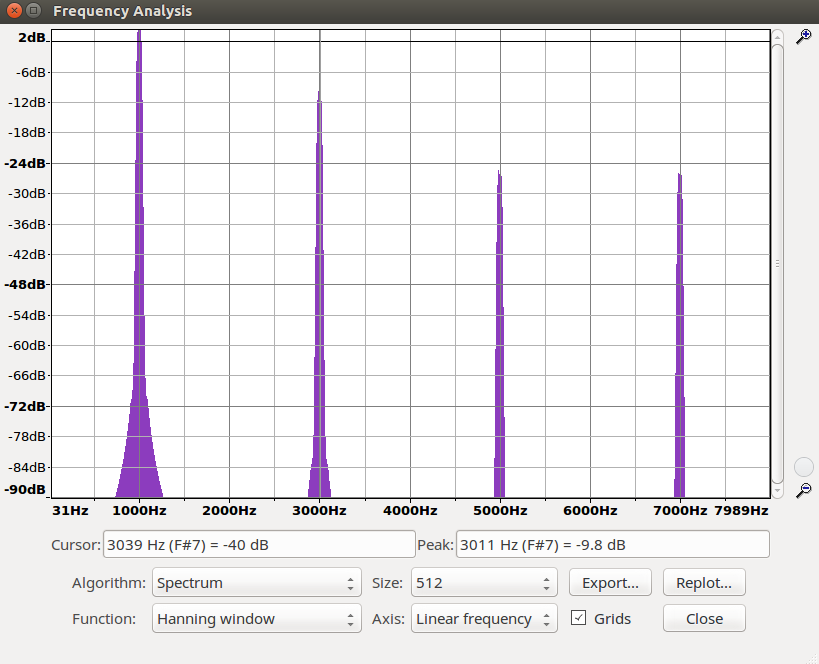
|
Ausschnitte vom Clipping
| sine wav | 6 dB | 9 dB | 12 dB |
|---|---|---|---|
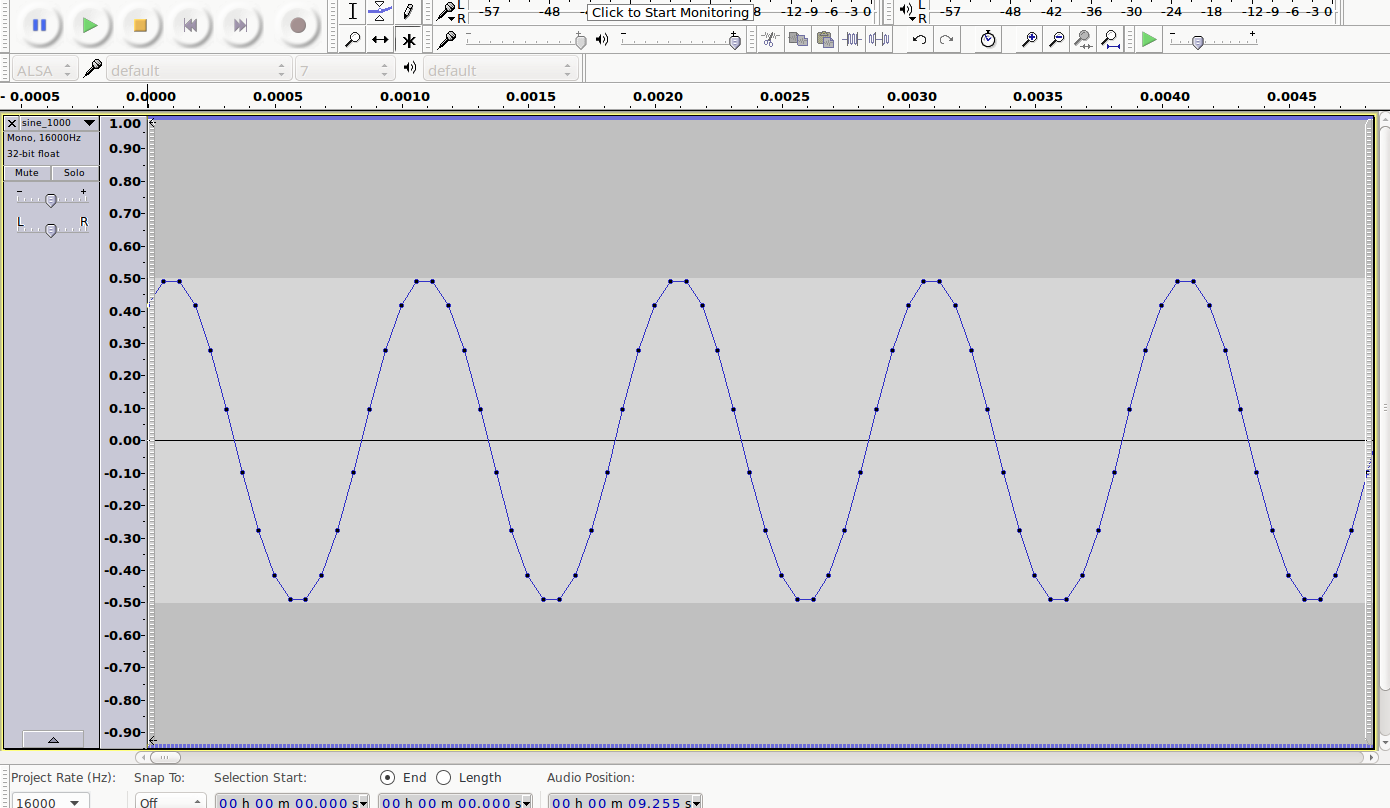 |
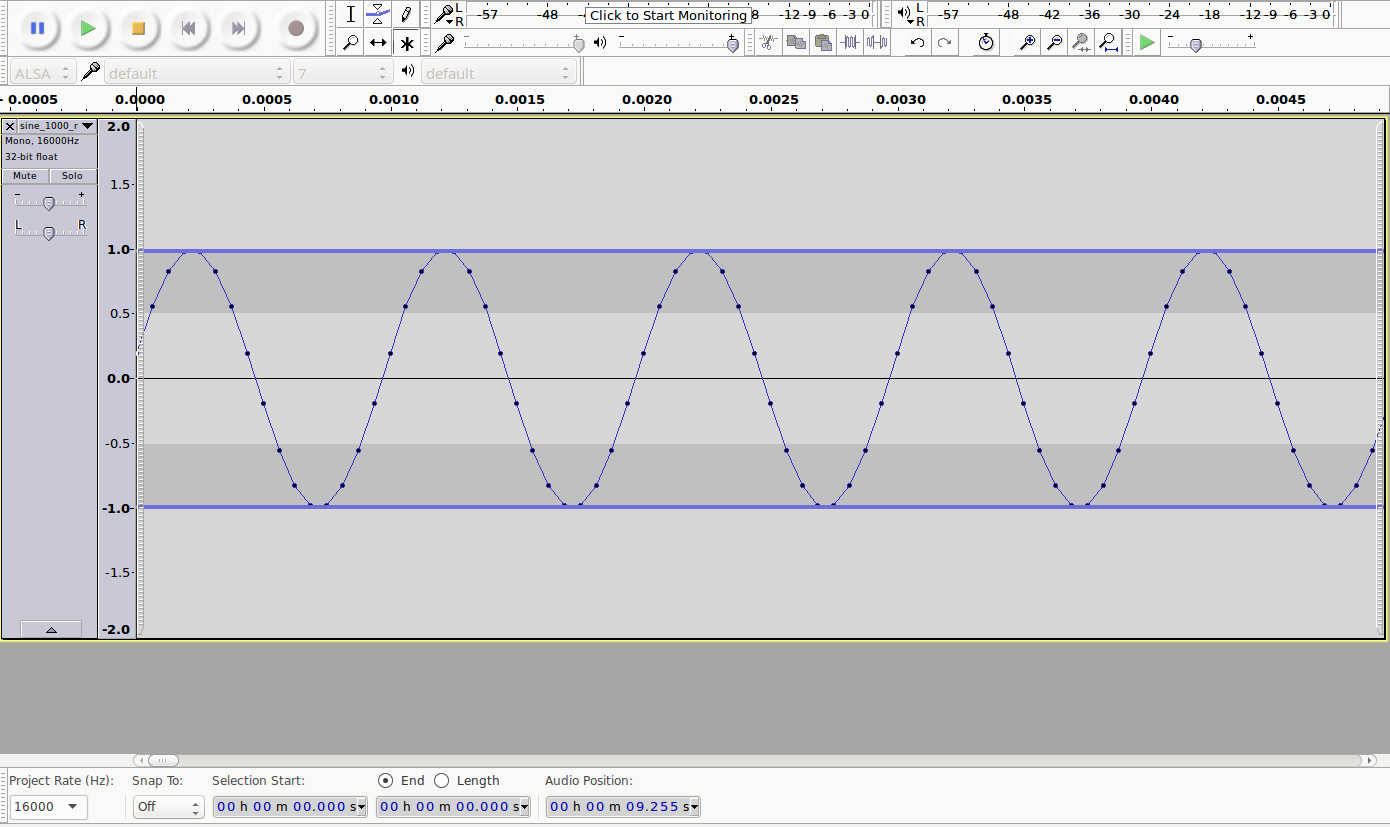 |
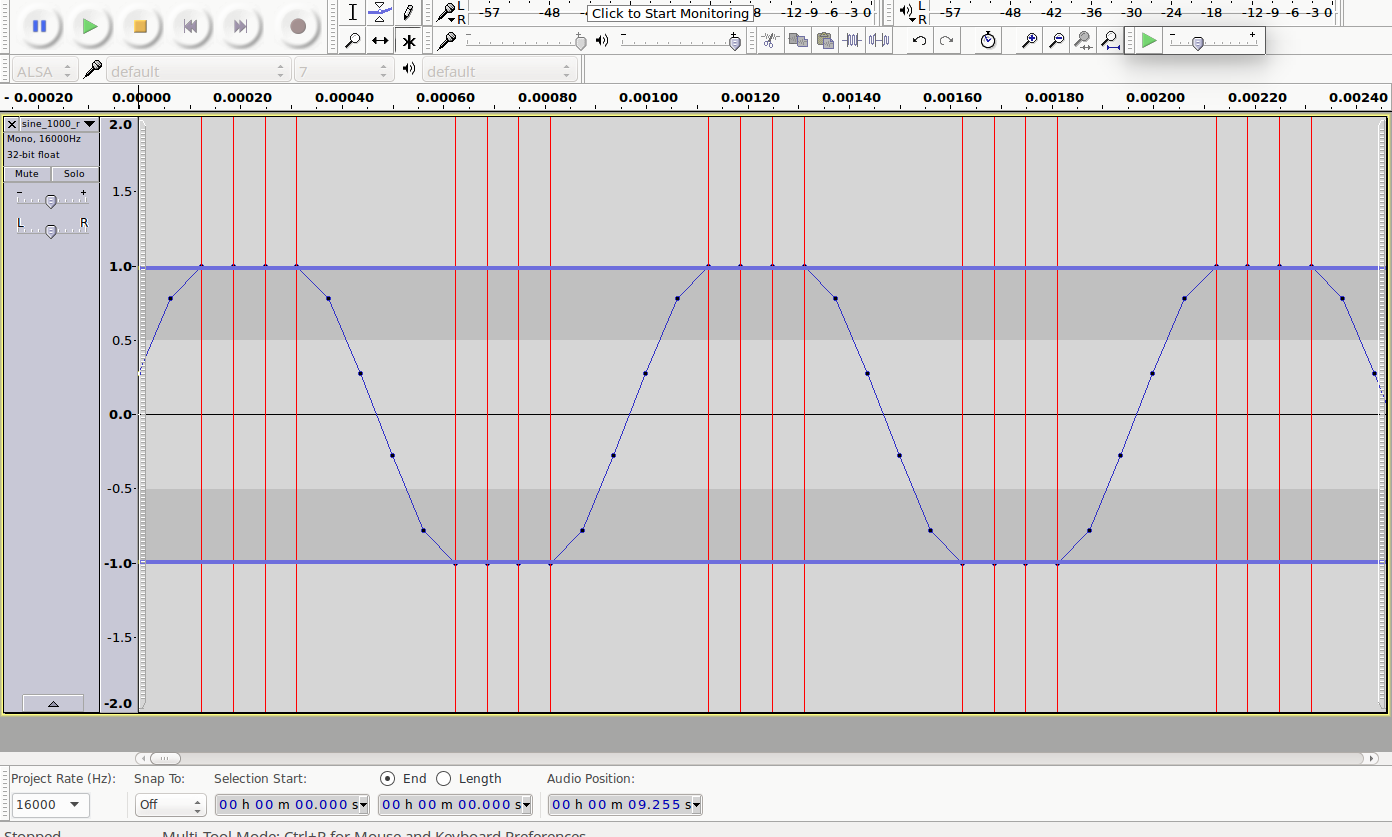
|
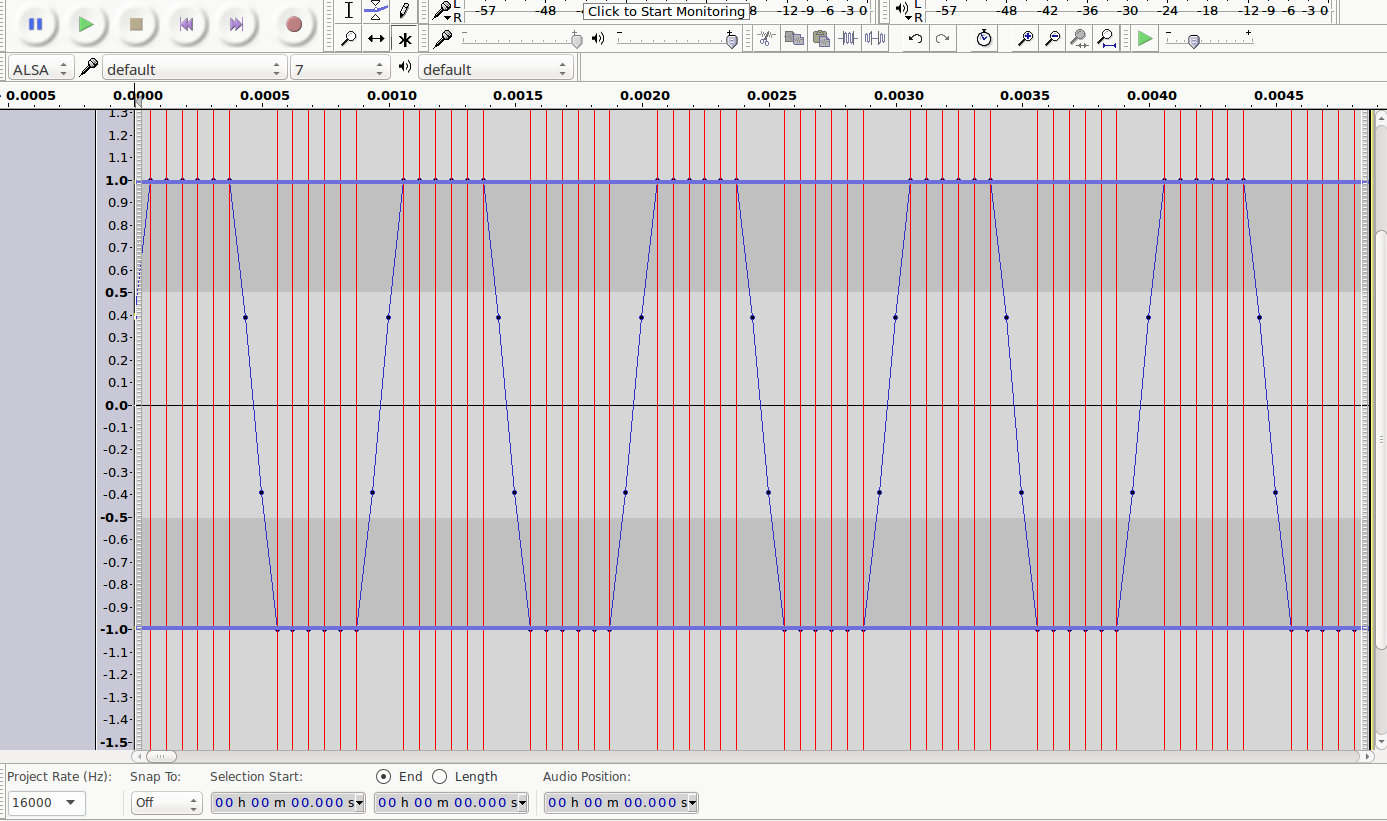
|
Ein wichtiger Effekt in der Studiotechnik ist das Echo. Dabei wird zu einem Signal eine zeitverzögerte und in der Amplitude gedämpfte Überlagerung hinzugemischt:
y(k) = x(k) + a * x(k-T), wobei T eine ganze Zahl zwischen 1 und N ist
a. Implementiert ein Echo mit einer Verzögerung von 10, 100 und 200ms und dem Verstärkungsfaktor a = 0.6. Wendet das Echo auf eure Sprach- und Musiksignal an. Es kann sein, dass die 10ms nur bei einem recht trockenen Soundfile wie der Sprachaufnahme
hörbar werden. Hinweis: Bei Stereodateien muss berücksichtigt werden, dass linker und rechter Kanal getrennt verzögert werden müssen. Die Samples für links und rechts liegen im Samplearray jeweils hintereinander. Es muss für den Ergebnissound ein neues
Objekt kreiert werden!
b. Um wieviel Abtastwerte müssen wir verzögern, wenn wir mit einer Abtastrate von 44.1 kHz arbeiten?
Ins Übungsprotokoll: Sourcecode, wavs Sprache und Musik
private static void echo_mono(String input, String output, double delay) throws IOException, WavFileException {
WavFile wavFile = WavFile.read_wav(input);
int validBits=wavFile.getValidBits();
long sampleRate=wavFile.getSampleRate();
long numFrames=wavFile.getNumFrames();
int numChannels=wavFile.getNumChannels();
int samples=(int)numFrames*numChannels;
int N = (int)((delay/1000) * sampleRate); // delay = delta t
short[] echo_sounds = new short[wavFile.sound.length];
for (int k=0; k < samples;k++) {
if (k >= N) echo_sounds[k] = (short) ((wavFile.sound[k] * 0.5) + (0.5 * 0.6 * wavFile.sound[k - N]));
else echo_sounds[k] = (short)(wavFile.sound[k] * 0.5);
}
WavFile.write_wav(output, numChannels, numFrames, validBits, sampleRate, echo_sounds);
}
private static void echo_stereo(String input, String output, double delay) throws IOException, WavFileException {
WavFile wavFile = WavFile.read_wav(input);
int validBits=wavFile.getValidBits();
long sampleRate=wavFile.getSampleRate();
long numFrames=wavFile.getNumFrames();
int numChannels=wavFile.getNumChannels();
int samples=(int)numFrames*numChannels;
int N = (int)((delay/1000) * sampleRate); // delay = delta t
N *= 2; // Für Stereo
short[] echo_sounds = new short[wavFile.sound.length];
for (int k=0; k < samples;k++) {
if (k >= N) {
echo_sounds[k] = (short) ((wavFile.sound[k] * 0.5) + (0.5 * 0.6 * wavFile.sound[k - N]));
}
else echo_sounds[k] = (short)(wavFile.sound[k] * 0.5);
}
WavFile.write_wav(output, numChannels, numFrames, validBits, sampleRate, echo_sounds);
}
Sprache 10 ms |
Sprache 100 ms |
Sprache 200 ms |
|---|---|---|
Musik 10 ms |
Musik 100 ms |
Musik 200 ms |
N = Verzögerung * Abtastfrequenz
N = 10 ms * 44.1 kHz = 441 Abtastwerte
N = 100 ms * 44.1 kHz = 4410 Abtastwerte
N = 200 ms * 44.1 kHz = 8820 Abtastwerte
a. Ein sehr einfaches Filter kann man z.B. mit der Zuordnungsvorschrift:
y(k) = 0.5 * x(k) + 0.45 * x(k-1)
realisieren. Programmiert das Filter und vergleicht die Musikdatei vor und nach der Filterung. Tut dasselbe mit der Zuordnungsvorschrift:
y(k) = 0.5 * x(k) - 0.45 * x(k-1)
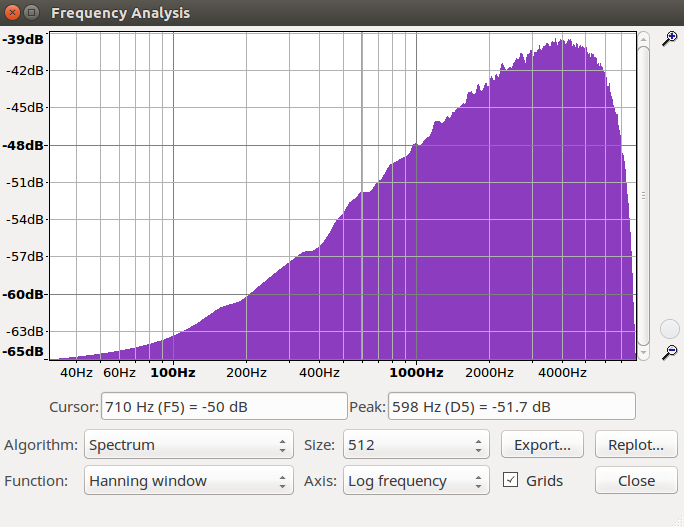
b. Zum Testen der Filter verwendet Weißes Rauschen, das alle Frequenzen enthält. Wenn wir nun den Frequenzverlauf des Originalaudios mit dem gefilterten vergleichen, muss sich ein Verlauf wie in der unteren Darstellung ergeben. Um eine Glättung
des Spektrums zu erzielen, bei GRAM 'Spectrum Average' auf 100 setzen. Um was für eine Art Filter handelt es sich jeweils?
Ins Übungsprotokoll: Sourcecode, wavs Musik und Rauschen, Frequenzverlauf GRAM
Filterimplementierung Sourcecode:
private static void filter_plus(String input, String output) throws IOException, WavFileException {
WavFile wavFile = WavFile.read_wav(input);
int validBits=wavFile.getValidBits();
long sampleRate=wavFile.getSampleRate();
long numFrames=wavFile.getNumFrames();
int numChannels=wavFile.getNumChannels();
int samples=(int)numFrames*numChannels;
// y(k) = 0.5 * x(k) + 0.45 * x(k-1)
short [] src = wavFile.sound;
short [] filtered = new short[wavFile.sound.length];
for (int i = 2; i < src.length; i++) {
filtered[i] = (short) (src[i] * 0.5 + 0.45 * src[i-2]);
}
WavFile.write_wav(output, numChannels, numFrames, validBits, sampleRate, filtered);
}
private static void filter_minus(String input, String output) throws IOException, WavFileException {
WavFile wavFile = WavFile.read_wav(input);
int validBits=wavFile.getValidBits();
long sampleRate=wavFile.getSampleRate();
long numFrames=wavFile.getNumFrames();
int numChannels=wavFile.getNumChannels();
int samples=(int)numFrames*numChannels;
//y(k) = 0.5 * x(k) - 0.45 * x(k-1)
short [] src = wavFile.sound;
short [] filtered = new short[wavFile.sound.length];
for (int i = 2; i < src.length; i++) {
filtered[i] = (short) (src[i] * 0.5 - 0.45 * src[i-2]);
}
WavFile.write_wav(output, numChannels, numFrames, validBits, sampleRate, filtered);
}
}
Musik wave |
Musik Filter plus |
Musik Filter minus |
|---|---|---|
Es handelt sich jeweils um einen Tiefpassfilter und um einen Hochpassfilter.
weißes Rauschen |
weißes Rauschen Filter plus |
weißes Rauschen Filter minus |
|---|---|---|
Frequenzverlauf
weißes Rauschen |
weißes Rauschen Filter plus |
weißes Rauschen Filter minus |
|---|---|---|
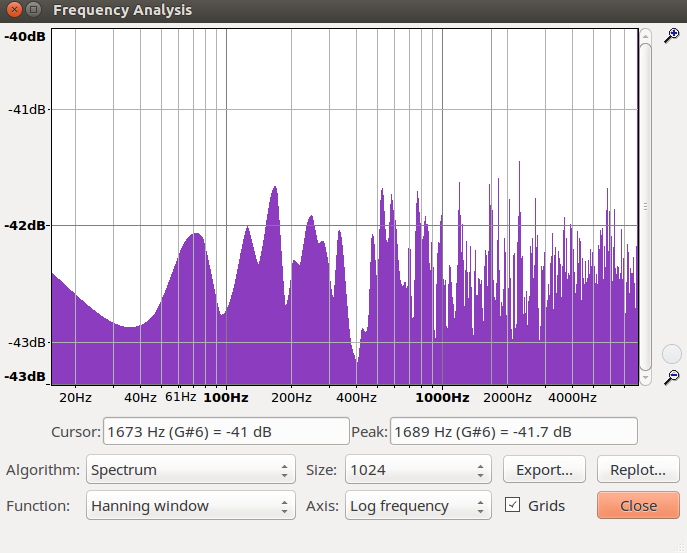 |
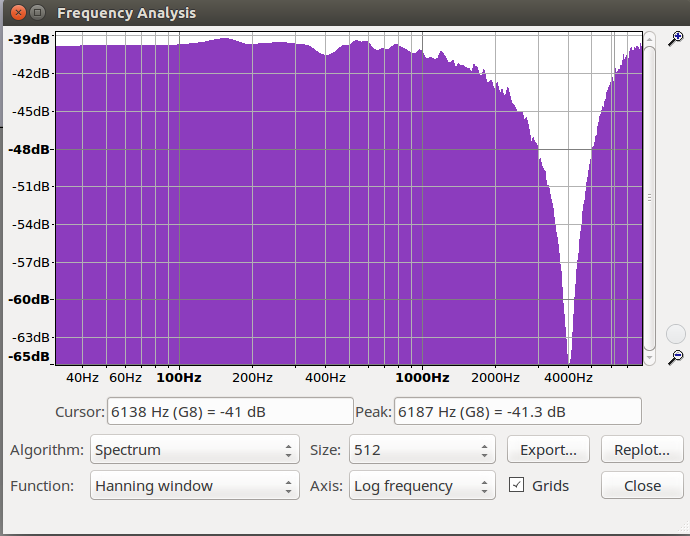 |
|